【Python3.x】BottleとJavaScriptを利用した非同期通信のファイルアップロード
BottlleはPythonで構築できる簡易Webサーバとして非常に重宝してるわけですが、非同期でのPOST通信のやり方が理解できたため、記載しておきます。
今回はテキストファイルのアップロードをさせます。
Windows10で実装していますが、Linuxの場合はファイルパス部分を適宜書き換えてください。
1.Bottleのインストール
engetu21.hatenablog.com
以前書いた方法(Bottleのファイルをダウンロードして使用)でもいいんですが、pipで入れた方がスマートなので、以下のコマンドで実施します。
python -m pip install bottle
python -m pip listbottle 0.12.25
2.Pythonファイルの作成
HTMLによる画面とPOSTの受信部を記述したPythonファイルを用意します。
JavaScriptも使うため、静的ファイルのパス等も記述します。
■C:\tmp\testApp\web.py
from bottle import route, request, run, static_file # JavaSciptファイルパス JQUERY_FILE = "/static/js/jquery-3.6.3.min.js" JS_FILE = "/static/js/function.js" CSS_FILE = "/static/css/style.css" # 静的ファイルパス STATIC_PATH = "C:/tmp/testApp/web/static//" # 初回画面のGET受信部 @route('/test-gamen', method='GET') def test_gamen() : string = "初回画面だよ" # HTML生成 return(html_create(string)) # 初回画面 def html_create(string) : return f''' <html> <head> <title>{string}</title> <script type="text/javascript" src="{JQUERY_FILE}"></script> <script type="text/javascript" src="{JS_FILE}"></script> <link rel="stylesheet" href="{CSS_FILE}" type="text/css"> </head> <body> <h1>{string}</h1> <form enctype="multipart/form-data"> ファイルを選択してください: <input type="file" id="files" name="files[]" accept=".txt"> <br> <input type="hidden" id="hidden_data" value="TESTtestTESTtest" /> <input type="button" value="登録" id="set_file" /> </form> <br> <div id="result_area"></div> <div id="overlay"> <div class="cv-spinner"> <span class="spinner"></span> </div> </div> </body> </html> ''' ### POST受信処理 @route('/post-uke-<string>', method='POST') def post_uke(string): try: upload = request.files.get('file') # アップロードファイルのファイル名取得(JavaScriptで事前に変更している) save_path = upload.filename # ヘッダからデータを取得 header = request.headers.raw("x-original-header") # アップロードされたバイナリデータをテキストファイルとして書き出し # 上書きを許容 upload.save("C:/tmp/testApp/file", overwrite=True) except Exception as e: return f"<span style='color:red'>テキストファイルアップロード失敗<br>エラー要因:{str(e)}</span><br>" try: # 対象ファイルのパス設定 path = r"C:\tmp\testApp\file" +"\\" + save_path # ファイル取り込処理 with open(path, encoding = 'UTF-8') as f: s = f.read() return f"<span style='color:blue'>{header}<br>{string}<br>{s}</span><br>" except Exception as e: return f"<span style='color:red'>テキストファイル読み込み失敗<br>エラー要因:{str(e)}</span><br>" # 静的ファイルのパス設定 @route('/static/<filepath:path>') def server_static(filepath): return static_file(filepath, root=f'{STATIC_PATH}') if __name__ == '__main__': run(host='0.0.0.0', port=9000, debug=False, reloader=True)
基本的な動きですが、ブラウザ→Python(GET)→JavaScript→Python(POST)となります。
POSTの送信はJavaScript内で記述していますので、後述のソースをご覧ください。
ここでは、Pythonプログラムでのいくつか注意点を記載します。
from bottle import route, request, run, static_file
末尾のstatic_fileを指定しないと静的ファイルを利用できないので注意。
<form enctype="multipart/form-data">
ファイルを選択してください: <input type="file" id="files" name="files[]" accept=".txt">
<br>
<input type="hidden" id="hidden_data" value="TESTtestTESTtest" />
<input type="button" value="登録" id="set_file" />
</form>このform内で設定している各種タグの「id」はJavaScript側でのデータ参照の際に使用できます。
JavaScript側のソースと照らし合わせて見るとわかるかと。
@route('/post-uke-<string>', method='POST')
def post_uke(string):ですが、この部分はPOSTのURLを可変にしたい場合に有効です。
例えば、以下のPOSTをJavaScript側から受け取ったとします。
post-uke-aaa
post-uke-bbb
この場合、2つとも@routeで定義してもいいのですが、今回のように<>で定義することで、「post-uke-」+ 何らかの文字列、という形で受信できます。
この際、@routeでアノテーションしているdefにて引数を指定します。
この引数はPOSTのURLで記述されている<>の中の文字列と同じものを指定します。
今回の場合は「string」という文字列を指定しています。
post-uke-aaa
post-uke-bbb
は許容したい、でも
post-uke-ccc
は受信したくない場合は?というと、
if string != "ccc" といった形で、条件分岐による処理を記述すればOK。
あるいは、aaaとbbbのみを許容し、elseでそれ以外は非許容とすればよい。
URLの可変部分については
/<iii>/<lll>/<mmm>
という形もできます。
その場合のdefの書き方は、
def post_uke(iii, lll, mmm):
です。
# アップロードされたバイナリデータをテキストファイルとして書き出し
# 上書きを許容
upload.save("C:/tmp/testApp/file", overwrite=True)アップロードされたテキストファイルは、バイナリデータでサーバに送られてくるため、
POST受信時に書き出しを行うようにします。
# 静的ファイルのパス設定
@route('/static/<filepath:path>')
def server_static(filepath):
return static_file(filepath, root=f'{STATIC_PATH}')静的ファイルを呼び出す際に必須な記述です。たしかBottleの公式ページに記載されていたと思います。
3.JavaScriptファイルの作成
ブラウザでボタンを押された際の挙動はJavaScriptで制御しています。
ファイル名を変更する処理をしていますが、これはファイル名に日本語しか入っていない場合、
アップロード時にファイル名が消えるだったか文字化けする現象があるためです。
本来はファイル名のエンコード処理が必要になるのですが、
割と面倒なので、ファイル名を一旦丸ごと変えるようにしています。
そこらへんが嫌な人は以下のサイトを参考にすれば、解消すると思います。
https://qiita.com/shimashima0109/items/d4d3f4ace8889456f822
https://magazine.techacademy.jp/magazine/23190
また、jqueryを使用しているため、jquery自体のファイルは以下から取得し、C:\tmp\testApp\web\static\js\に格納してください。
記載したプログラム上は、jquery-3.6.3.min.jsを使用しています。
https://jquery.com/download/
■C:\tmp\testApp\web\static\js\function.js
$(function() { //_/_/_/_/_/_/_/ ファイル登録処理 _/_/_/_/_/_/_/ $('#set_file').click(function() { // メッセージ部分初期化 $('#result_area').html(``) // 連続クリック抑止(スピナーを表示してるから多分いらない) $('#set_file').disabled = true; // アップロードファイルの取得 const files = $('#files').prop('files'); // アップロードされたファイルが日本語、記号のみの場合、ファイル名が正常に認識されない(除外される?)ため、 // ファイル名を差し替えを行う const newName = "ChangedName.txt" const fd = new FormData(); fd.append('file', files[0], newName); // files[0]はpythonプログラムの「input type="file"」で指定しているnameのゼロ番目(だったはず) const hidden= $('#hidden_data').val() // hiddenのデータは#とhiddenタグでつけたidを指定することで取得することが可能 // こうやればファイル名を取得することが可能 const file_name = files[0].name; //console.log(file_name); post_url = 'post-uke-' + file_name // Ajax実行前にクルクル(スピナー)を表示 $(document).ajaxSend(function() { $("#overlay").fadeIn(300); }); // post実行 $.ajax(post_url, { type: 'post', headers: { 'x-original-header': hidden}, data: fd, processData: false, contentType: false, dataType: 'text' }) // 登録成功時にはページに結果を反映 .done(function(data) { setTimeout(function(){ $("#overlay").fadeOut(300); },500); //console.log(data); $('#result_area').html(`${data}`) }) // 登録失敗時には、その旨をダイアログ表示 .fail(function(XMLHttpRequest, status, e) { window.alert('ファイル登録に失敗しました\nエラー内容:' + e); }); }); });
基本的にはコメントで記載している通りなので、特に解説することはないのですが、
POSTにファイルを送る場合、ボディ部(データ部)はファイルのバイナリデータで埋まってしまうため、何らかのデータをPOSTに付け足したい!といった場合は、オリジナルのヘッダを用意して設定するか、POSTのURLで情報を送る必要があると思われます。(他にもやり方があるかも)
4.CSSファイルの作成
スピナー(くるくる)を表示するために定義しています。
これはネットでの拾い物となるため、それをそのまま利用しました。
なので、解説することは何もないです。
■C:\tmp\testApp\web\static\css\style.css
#overlay{
position: fixed;
top: 0;
z-index: 100;
width: 100%;
height:100%;
display: none;
background: rgba(0,0,0,0.6);
}
.cv-spinner {
height: 100%;
display: flex;
justify-content: center;
align-items: center;
}
.spinner {
width: 40px;
height: 40px;
border: 4px #ddd solid;
border-top: 4px #2e93e6 solid;
border-radius: 50%;
animation: sp-anime 0.8s infinite linear;
}
@keyframes sp-anime {
100% {
transform: rotate(360deg);
}
}
.is-hide{
display:none;
}
5.画面確認
作成したPythonファイルを実行します。
> cd C:\tmp\testApp
> python web.py
ブラウザで以下のURLにアクセス。
http://localhost:9000/test-gamen
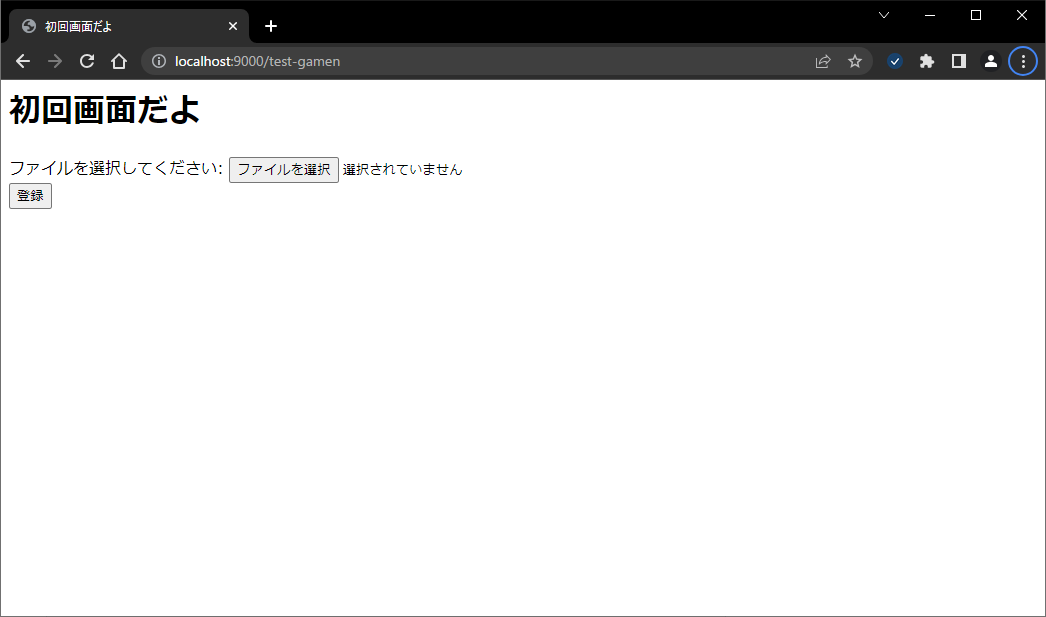
aaa.txtというファイルを指定します。中身は以下の通り。
ああああああああああああああああああああああああああ
いいいいいいいいいいいいいいいいいいいいいいいいいい
これをアップロードすると、以下のように表示されます。
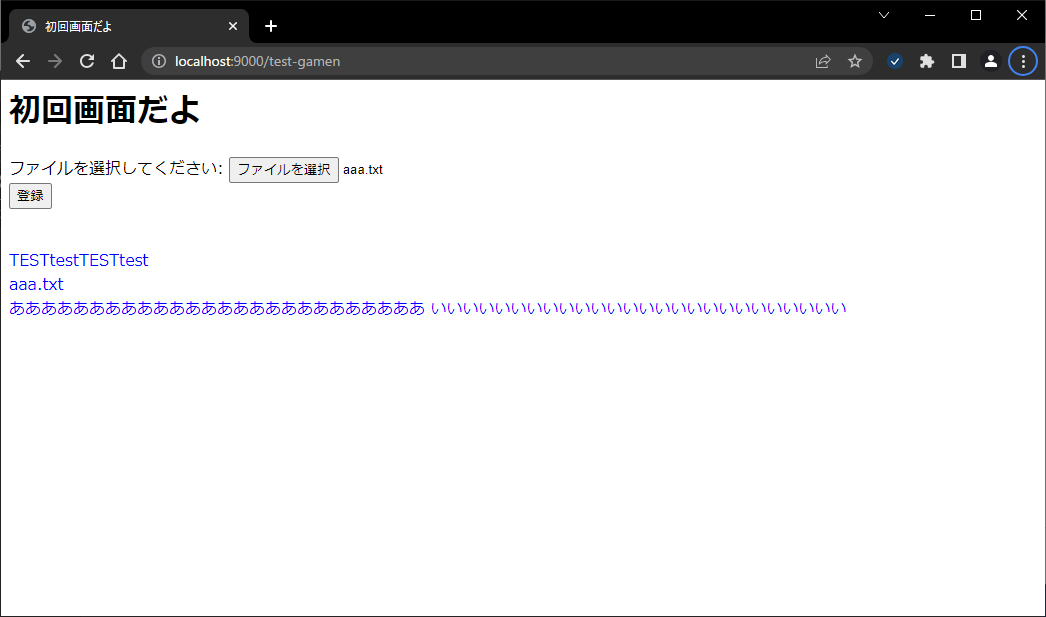
青文字1行目はform内でhiddenで設定した文字列です。これはPOSTのヘッダに載せたものを表示しています。ページの右クリックでソースを表示してhiddenの値は確認できます。
青文字2行目はアップロードされたファイルの名前です。これはPOSTのURLとして付与された文字列を表示しています。
青文字3行目はテキストファイルの中身です。特に工夫せずそのまま表示していますが、忠実に再現するなら、改行コードをbrタグに変更してやるなどの対応が必要です。
というわけで、Bottleで簡易的にPOSTを使いたい、ファイルアップロード画面を作りたいといった場合にはこんな感じでできると思います。
元々作っていたのはExcelファイルアップロード画面で、今回は簡単に説明できるようテキストファイルとしました。
Excel取り込みの方はDataFrameを利用するのでより複雑なのですが、それに関してはまた記事にしていこうかなと思います。
【Windows Server2019】Grafana LokiとPromtailのインストールとセッティング、Grafanaとの連携
Pythonで作ったプログラムのログを収集し、Grafanaで見えるようにするにはどのようにしたらよいか?
Prometheusのエクスポータに「grok_exporter」というものがあるのですが、これを利用することでログ監視をすることは可能です。
ただし、grok_exporterをWindows機で利用するためにはクロスコンパイルしたもの(Windowsで使うために他のマシンのLinux上でコンパイルを行う)が必要となり、とても面倒です。
grok_exporterを利用するのではなく、別の手段を探したところ、「Grafana Loki」(ロギングエンジン)にてログ集約が行えるようなので、そちらで実現したいと思います。
・Grafana Loki
ログデータの収集、保存、クエリ、可視化を目的としたオープンソースのログ集約システムです。Lokiは、Prometheusと同じくCloud Native Computing Foundation(CNCF)のプロジェクトとして開発されています。
By chatGPT
ただし、ログの収集自体はできないため、推奨されている「Promtail」か「Fluentd」等を使用する必要があります。
- 1.Grafana Loki、Promtailのインストール
- 2.Loki設定ファイルの設定変更
- 3.Promtail設定ファイルの設定変更
- 4.Grafana Lokiの起動
- 5.Promtailの起動
- 6.Grafanaの設定
- 7.蛇足
1.Grafana Loki、Promtailのインストール
以下のページの下部にあるWindows用インストールファイルをダウンロードします。
https://github.com/grafana/loki/releases/
loki-windows-amd64.exe.zip
promtail-windows-amd64.exe.zip
※画面上に表示されていない場合は「Show all XX assets」を押下し、表示します。
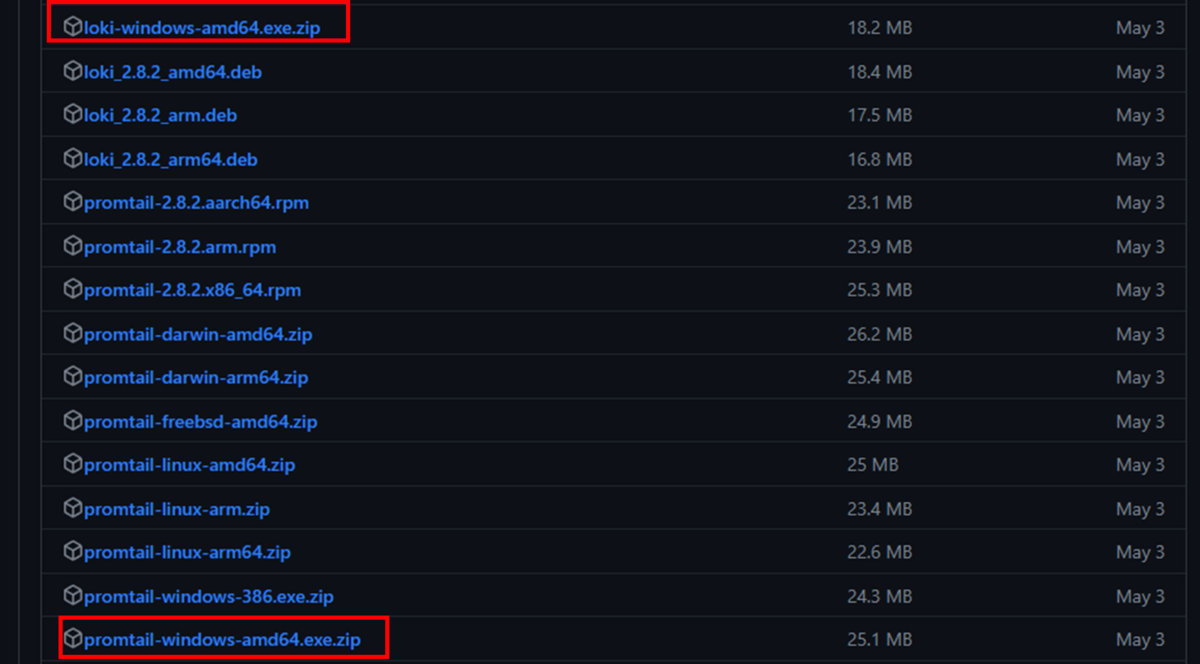
2つのzipファイルを解凍し、適切な場所にフォルダを配置します。
例)C:\systemwatch\loki、C:\systemwatch\promtail
Loki実行ファイル:loki-windows-amd64.exe
Promtail実行ファイル:promtail-windows-amd64.exe
取得できるのは実行ファイル(EXEファイル)のみとなり、設定ファイルは別途用意する必要があります。
ブラウザを起動し、以下のURLにアクセスして設定ファイルをダウンロードします。
※ダウンロードできず、設定ファイルの中身がブラウザ画面に表示された場合は、
その表示内容をコピーし、ローカルにアクセス先と同一名称のyamlファイルを作成し、内容のペーストを行う。
https://raw.githubusercontent.com/grafana/loki/main/cmd/loki/loki-local-config.yaml
https://raw.githubusercontent.com/grafana/loki/main/clients/cmd/promtail/promtail-local-config.yaml
ダウンロードした設定ファイルは、実行ファイルと同一のフォルダに格納します。
2.Loki設定ファイルの設定変更
設定ファイルに記載されているファイルパスは、Linuxに準拠した形で記載されています。
例えば「path_prefix: /tmp/loki」といった形で設定されていますが、実をいうとこのままでも動作は可能。
(その場合、C:¥の直下にtmpフォルダ以下が作成される)
フォルダパスについては、以下の様に実行フォルダ配下となるよう、絶対パスを指定する。
loki-local-config.yaml
path_prefix: /tmp/loki ↓ path_prefix: C:/systemwatch/loki/tmp/loki chunks_directory: /tmp/loki/chunks ↓ chunks_directory: C:/systemwatch/loki/tmp/loki/chunks rules_directory: /tmp/loki/rules ↓ rules_directory: C:/systemwatch/loki/tmp/loki/rules
3.Promtail設定ファイルの設定変更
Loki設定ファイルと同様、ファイルパスの変更を行います。
promtail-local-config.yaml
filename: /tmp/positions.yaml ↓ filename: C:/systemwatch/promtail/positions.yaml
また、ログ収集の対象となるファイルの指定は、この設定ファイル内で記載する必要があります。
「scrape_configs:」以下に、収集するログ毎に「-job_name」を記述します。
__path__にパスを設定します。アスタリスクによる指定も可能です。
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: C:/systemwatch/promtail/positions.yaml
clients:
- url: http://localhost:3100/loki/api/v1/push
scrape_configs:
- job_name: logs
static_configs:
- targets:
- localhost
labels:
job: logs
__path__: C:/DataDirectory/logs/*.log
pipeline_stages:
- match:
selector: '{job="logs"}'
stages:
- regex:
expression: '^(?P<time>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}\,\d{3}) .*$'
- timestamp:
source: time
format: '2006-01-02 15:04:05.000'
location: Asia/Tokyoデフォルト設定では、Promtailで収集された日時がそのままタイムスタンプとして管理されます。
しかしその場合、Pythonのloggerで出力したログの中にも存在するログ出力時間と食い違いが発生してしまい、
Grafanaでのソート処理にて正常にソートされなくなってしまいます。
その対策として、ログ内にあるログ出力時間をPromtailのタイムスタンプと一致させるため、以下の対応を行います。
ログは「2023-06-26 16:59:38,646 [ERROR] エラー要因:TESTTEST」の形とします。
・pipeline_stages>match>stages>regexのexpression項にて、[time]という変数に正規表現(Google/RE2)を設定する。
・pipeline_stages>match>stages>timestampにて、regexで用意した[time]をsourceに指定し、
formatをカスタム設定する。(カスタム設定の場合の設定値は参考欄のtimestampについてのURLを参照)
・正規表現については以下の通り
^:先頭を示す
?P
■参考
pipelinesについて:https://grafana.com/docs/loki/latest/clients/promtail/pipelines/
RE2:https://github.com/google/re2/wiki/Syntax
timestampについて:https://grafana.com/docs/loki/latest/clients/promtail/stages/timestamp/
設定の参考ブログ:https://blog.yiwkr.work/2020-09-01-promtail-timestamp
また、Windows Serverのイベントログを取得する場合は、設定ファイルに以下の内容を追加することでWindows Serverのイベントログを取得することが可能となります。
promtail-local-config.yaml
- job_name: windows
windows_events:
use_incoming_timestamp: false
bookmark_path: "C:/systemwatch/promtail/bookmark.xml"
eventlog_name: "Application"
xpath_query: '*'
labels:
job: windows
relabel_configs:
- source_labels: ['computer']
target_label: 'host'
■参考
https://grafana.com/docs/loki/latest/clients/promtail/scraping/#windows-event-log
4.Grafana Lokiの起動
PowerShellを実行し、実行ファイルがあるフォルダに移動後、以下のコマンド実行します。
※実行時に設定ファイルを指定する。
> cd C:\systemwatch\loki
> .\loki-windows-amd64.exe --config.file=loki-local-config.yaml
以下のメッセージがあれば起動が完了する。
level=info ts=2023-06-07T09:42:31.1513442Z caller=loki.go:499 msg="Loki started"
level=info ts=2023-06-07T09:42:34.0927708Z caller=scheduler.go:681 msg="this scheduler is in the ReplicationSet, will now accept requests."
level=info ts=2023-06-07T09:42:34.0927708Z caller=worker.go:209 msg="adding connection" addr=127.0.0.1:9096
level=info ts=2023-06-07T09:42:36.1515776Z caller=compactor.go:411 msg="this instance has been chosen to run the compactor, starting compactor"
level=info ts=2023-06-07T09:42:36.1515776Z caller=compactor.go:440 msg="waiting 10m0s for ring to stay stable and previous compactions to finish before starting compactor"
5.Promtailの起動
PowerShellを実行し、実行ファイルがあるフォルダに移動後、以下のコマンド実行します。
※実行時に設定ファイルを指定する。
> C:\systemwatch\promtail
> .\promtail-windows-amd64.exe --config.file=promtail-local-config.yaml
※実行時に「mapping values are not allowed in this context.」というエラーが出た場合、
インデントが誤っていたり、「項目: 設定値」の記述で、:の後ろに半角スペースが無いなどを確認する必要あり。
例)
○ job: aaa_logs
× job:aaa_logs
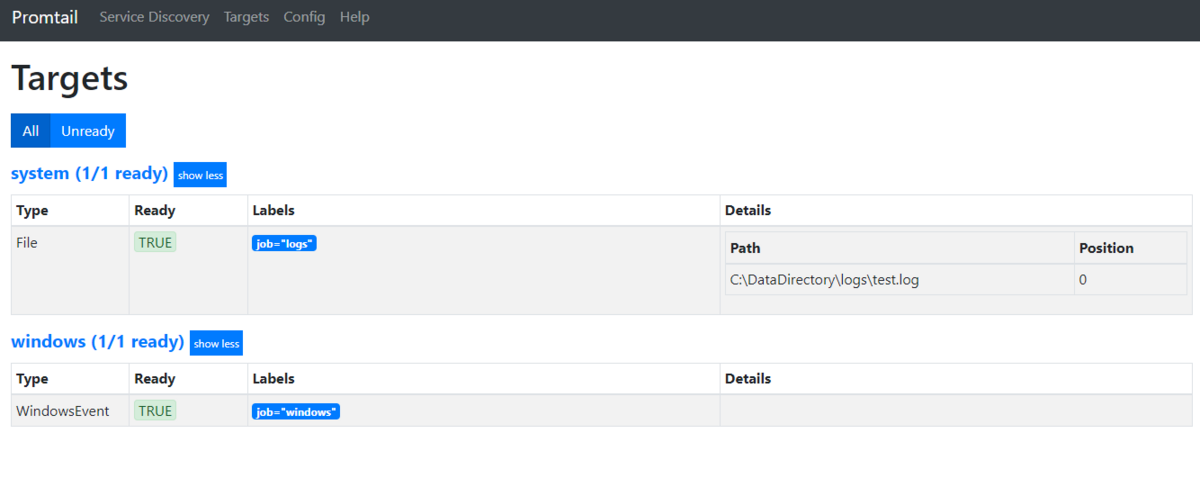
設定ファイルで指定したパスで該当するファイルを以下のURLから確認することが可能です。
ポート番号は、設定ファイルのhttp_listen_port項で指定しているポート番号となります。
http://localhost:9080/
6.Grafanaの設定
GrafanaのConnectionsにてデータソースとしてGrafana Lokiを設定し、連携させます。
やり方は以前取り上げた以下の記事を参照。
engetu21.hatenablog.com
URLの部分のポート番号は、Granafa Lokiの設定ファイルと同様のものを指定。デフォルトは3100。
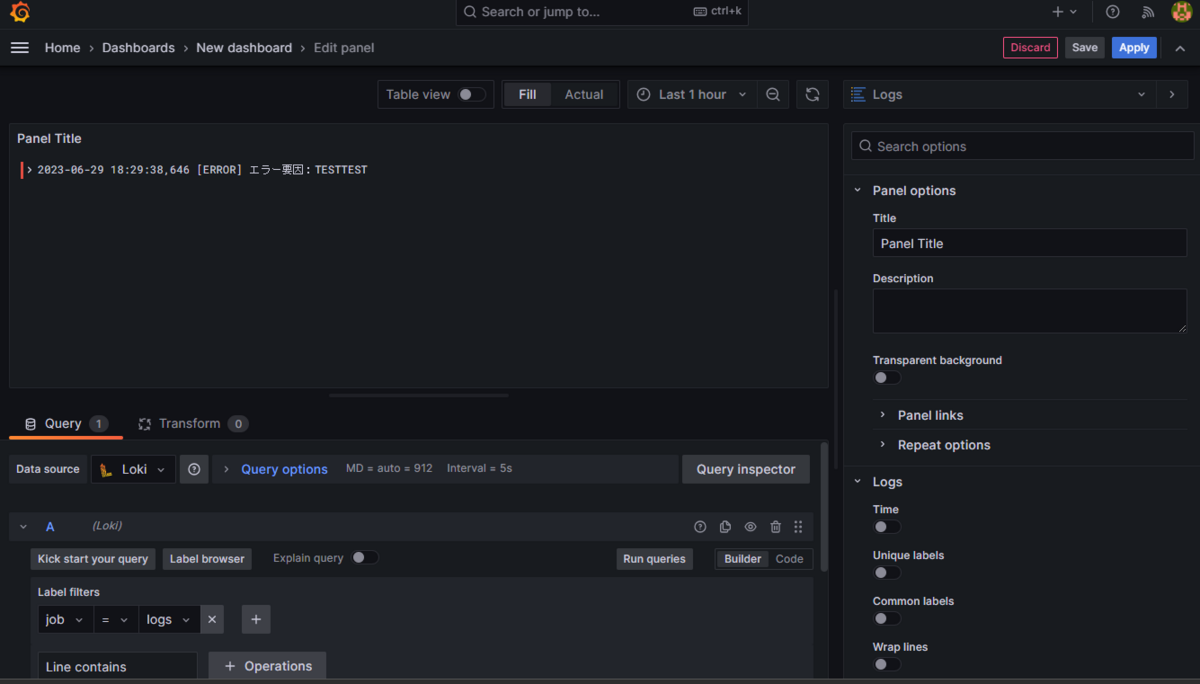
ダッシュボードに移動し、新しくパネルを作ります。
Data sourceの欄に「Loki」が増えているため、それを選択。
Label Filtersを「job = logs」(logsは設定ファイルで設定したjob: logsの部分です)を選択。
右上のグラフの種類で「Logs」を選択し、[Run queries]を押下すれば、ログが表示されます。
※ログが表示されない場合は、ログが出力されているであろう時間帯にグラフを変更してください。
このままApplyを押下することで、ダッシュボードに反映されます。
7.蛇足
今回はPythonで出力したログファイルをPromtailで収集し、Grafana Lokiにて管理していますが、Python⇒Grafana Lokiに直接ログを送ることも可能なようです。
今回はその対応を行っていませんが、対応する場合は以下を参照し、Pythonでライブラリを導入することで対応が可能と思われます。(2023/6/29現在)
https://medium.com/geekculture/pushing-logs-to-loki-without-using-promtail-fc31dfdde3c6
【Windows Server2019】Grafanaのインストールとセッティング
Grafanaとは?
Grafanaは、データの可視化やダッシュボードの作成を目的としたオープンソースのモニタリングツールです。Grafanaは、さまざまなデータソースからデータを収集し、リアルタイムで可視化や分析を行うことができます。
By chatGPT
というわけで、Prometheusで取得したデータをGrafanaにて表示します。
1.ファイルのダウンロード
以下のページから最新版かつOSSエディション、かつWindows版をダウンロードします。
ただし、最新版が出たばかりの状態は情報が少なく枯れてもいないため、それ以前のバージョンを使用します。
今回の対象は9.5.5とします。
インストーラ版でもいいですが、今回はStandalone Windows Binaries欄のzipの方をダウンロード。
https://grafana.com/grafana/download
適切な場所にファイルを移動を行う
例)C:\systemwatch\grafana-9.5.5
2.設定ファイルの設定変更
基本的にはデフォルト設定のままで動作するため、変更の必要はなし。
ポート変更が必要な場合は以下の様にconf配下のdefaults.iniで変更を行います。
.\conf\defaults.ini
http_port = 3000
↓
http_port = 3001
3.Grafana実行
C:\systemwatch\grafana-9.5.5\bin\grafana-server.exe
をダブルクリックすることで実行可能。
以下のURLにてアクセスが可能。
初回ユーザは以下の通り。
http://localhost:3000/
ユーザ:admin
パスワード:admin
※ログイン後パスワード変更を求められる
4.データソースの追加
Prometheusのデータソースとの連携を行う。
メニューから [Connections] > [Data sources]と辿り、[ Add data source]をクリック。
「Prometheus」をクリックします。
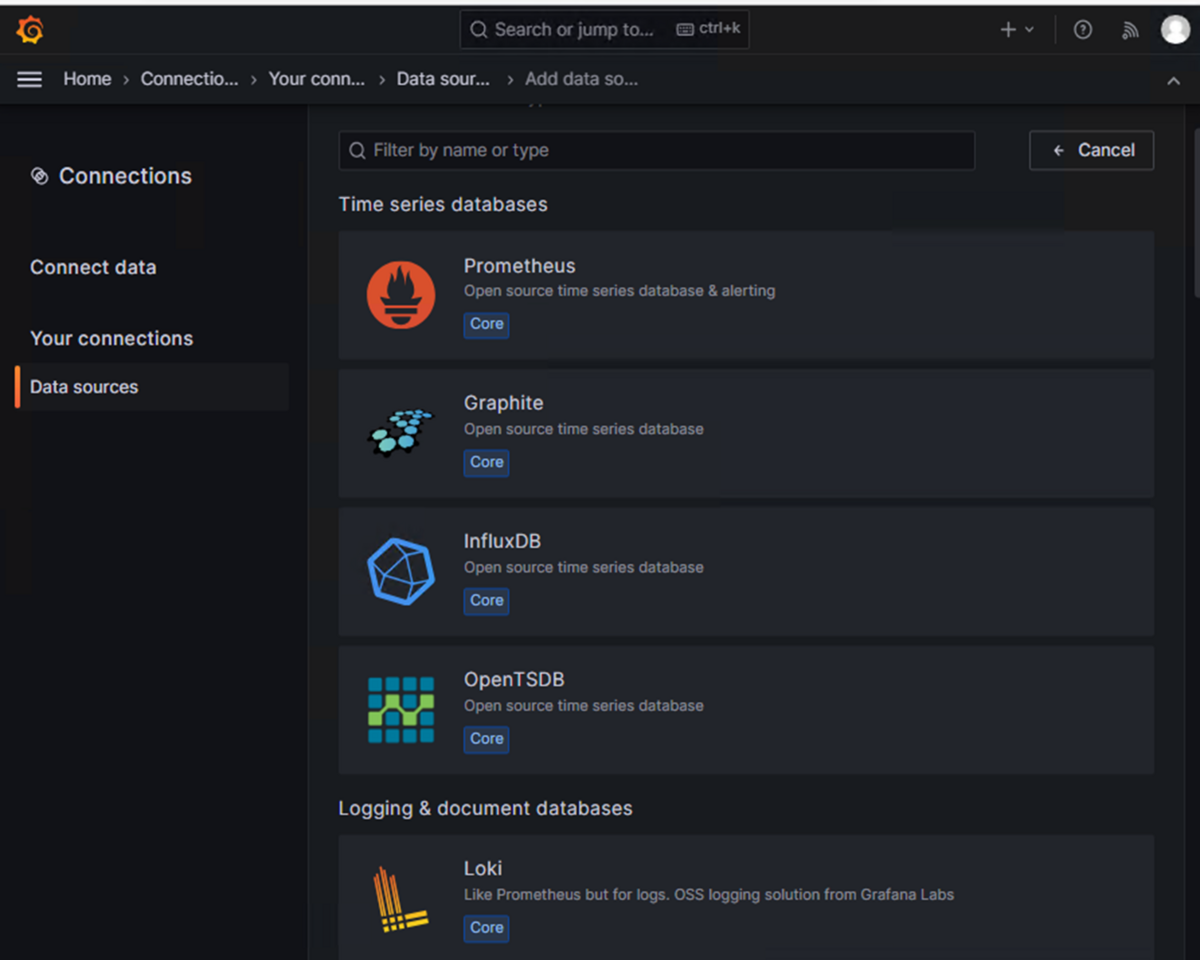
URL欄を設定します。それ以外の設定値は特に設定を変更する必要なし。
Prometheus:http://localhost:9095
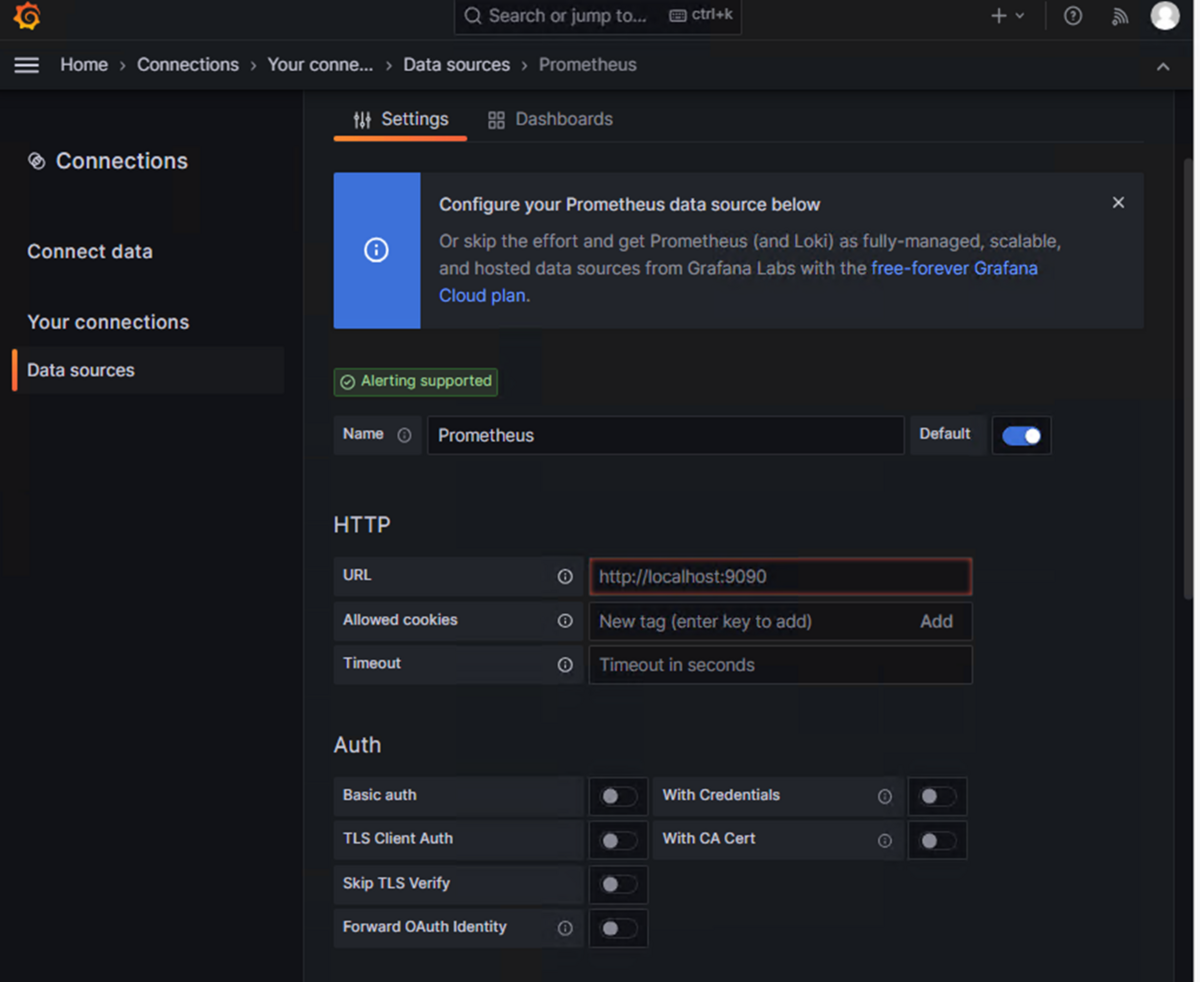
[Save & test]をクリックし、「Data source is working」と表示されれば連携完了。
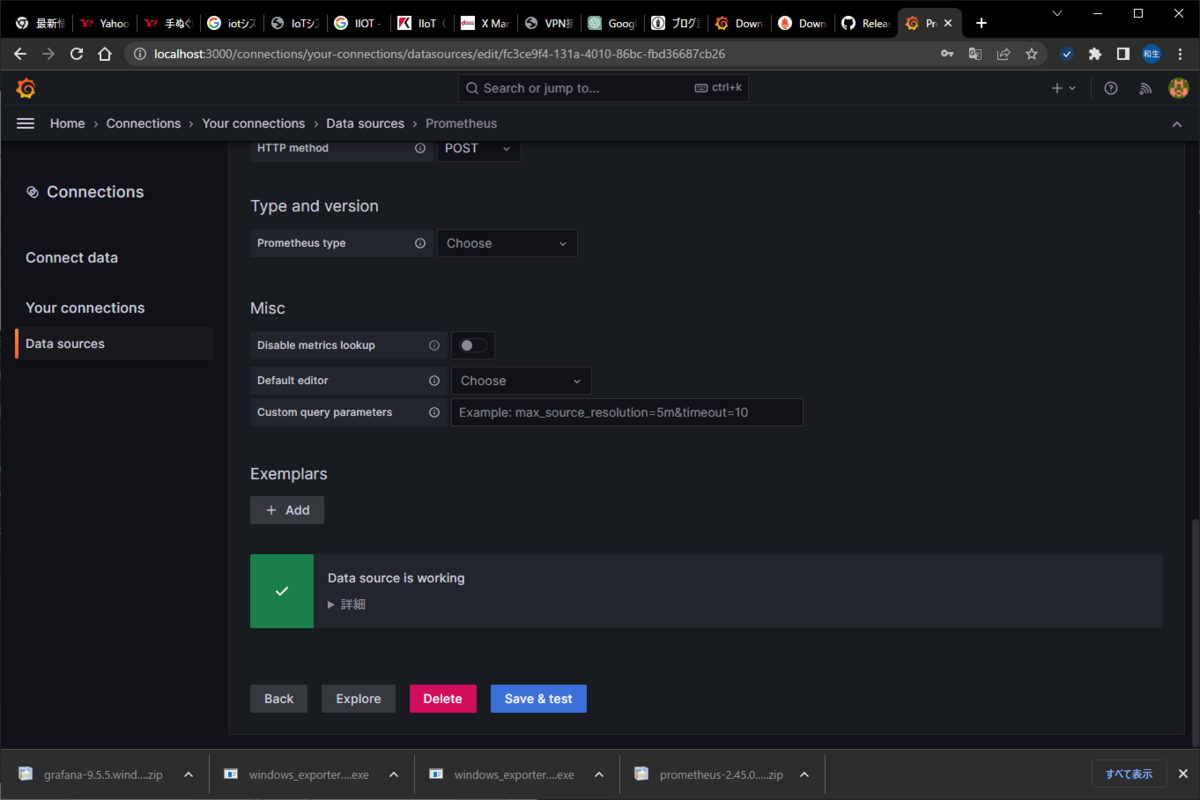
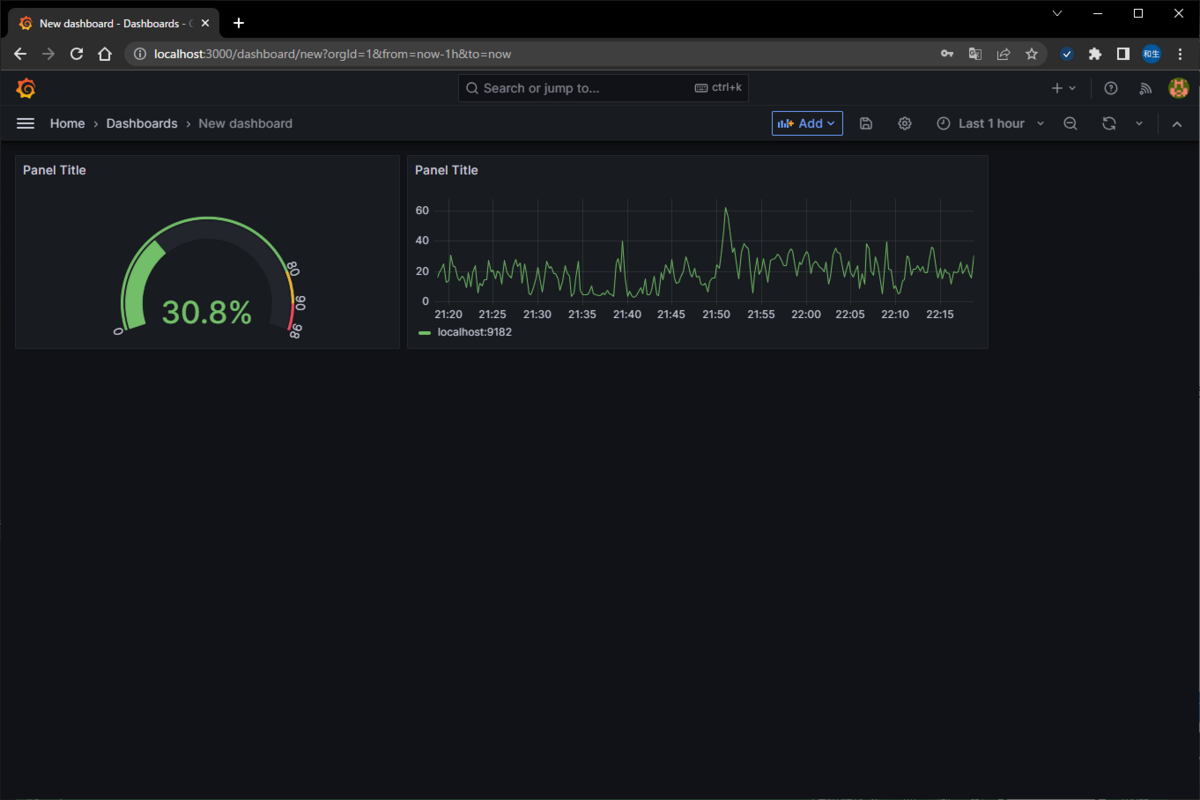
5.ダッシュボード作成
ダッシュボードを作成し、Pythonで作成したアプリのログの表示やWindowsServerのリソース状況を確認します。
メニューのHome > Dashboardsを辿り、[New]→[Add visualization]ボタンで作成が可能。
Data source欄にて「Prometheus」を選択し、連携ができていればMetric欄にてコマンドが表示されるため、選択することでwindowsServerの各種リソース情報などを表示することが可能です。
今回は
engetu21.hatenablog.com
で記載したCPU使用率を使って作成します。
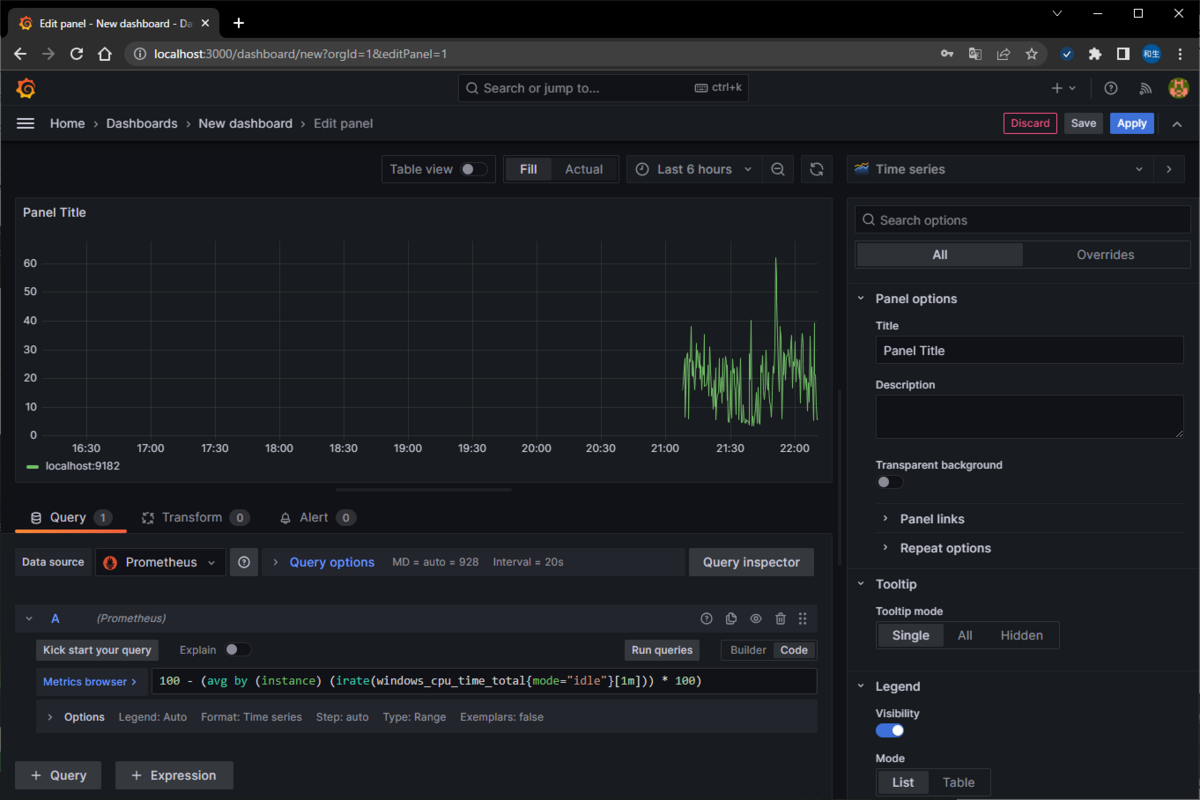
直接入力する場合は[Code]を押下し、Metrics browserに
100 - (avg by (instance) (irate(windows_cpu_time_total{mode="idle"}[1m])) * 100)
を入力します。
その後に[Run queries]を押下し、クエリを実行。
表示するとこんな感じ。
6.CPU使用率をタコメーターのように表示
グラフの種類を変更し、タコメーターのように変更します。
タコメータのように表示する場合は、右欄のグラフ種類にて「Gauge」を選択。
目盛りを表示する場合は「Show threshold labels」をON。
メータ全体を表す細い線を表示する場合は「Show thresholdmarkers」をON。
パーセントで表示する場合はStandard optinsのUnitを「Misc」→「Percent(0-100)」を指定。最大値、最小値としてMin:0/MAX:100を設定。
画像の様に80%以上の場合に色を変更する場合などは、[Add threshold]を押下し、新規に定義を作成する。
また、Value options のCalculationの欄にて「Last *」か「Last」を指定することで、最新の内容を表示する形となる。
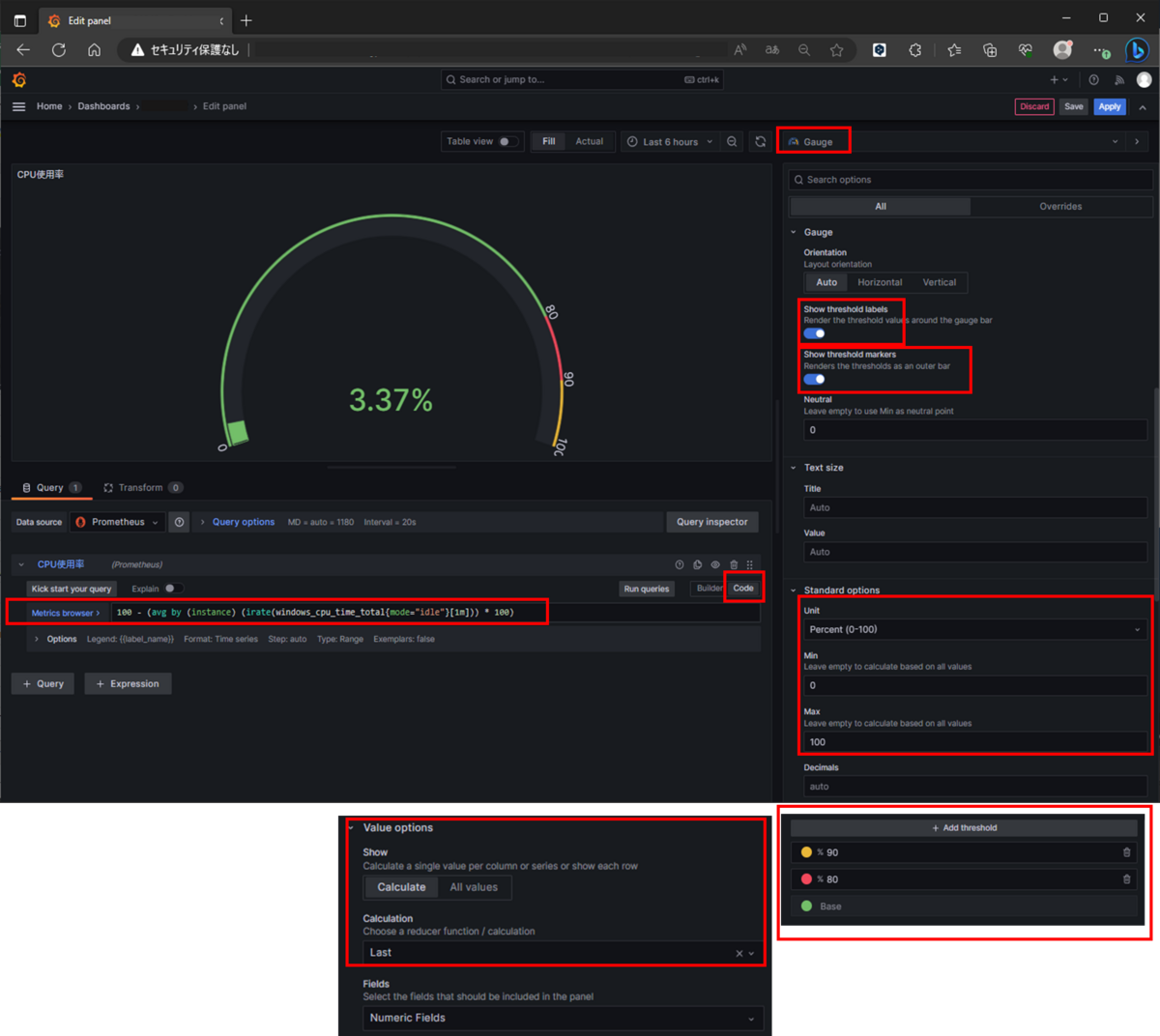
作成したパネルは右上の[Apply]を押下することで作成完了。
同じ要領で時系列データをグラフ化することが可能です。
【Windows Server2019】Prometheusインストールとセッティング
Prometheus(プロメテウス)とは?
Prometheusは、オープンソースのシステムおよびサービスの監視およびアラーティングシステムです。Prometheusは、GoogleのBorgmonシステムからインスピレーションを得て開発され、2012年に公開されました。現在は、Cloud Native Computing Foundation(CNCF)のプロジェクトとしてホストされています。
Prometheusは、高度に拡張可能なデータモデルと柔軟なクエリ言語を提供し、システムやアプリケーションのメトリクス(指標)を収集、保存、可視化、アラーティングするための機能を提供します。
By chatGPT
というわけで、Prometheusをインストールし、リソース管理できるようにします。
また、最終的にはGrafanaと連携し、そちらでダッシュボードを作成します。
- 1.Prometheusのダウンロード
- 2.windows_exporterのダウンロード
- 3.Prometheusの設定ファイル変更
- 4.Prometheusの実行
- 5.ブラウザにて以下のURLにアクセスを行う
1.Prometheusのダウンロード
以下からPrometheusのWindows版、かつLTS版を取得します。(現時点は2.45.0)
https://prometheus.io/download/
zipファイルを解凍し、適切な場所にフォルダを配置します。
例)C:\systemwatch\prometheus
2.windows_exporterのダウンロード
windows_exporterを使うことでWindows機のリソース監視を行うことができるようになります。
EXEファイルを以下からダウンロード。
https://github.com/martinlindhe/wmi_exporter/releases
windows_exporter-0.22.0-amd64.exe
PowerShellを起動し、ダウンロードした先に移動。
以下のコマンドで実行を行います。
> .\windows_exporter-0.22.0-amd64.exe
3.Prometheusの設定ファイル変更
解凍したフォルダ配下のprometheus.ymlの内容を以下に変更。
ポート変更によって、windows_exporterを利用した監視が可能となります。
prometheus.yml
static_configs:
- targets: ["localhost:9090"]
↓
static_configs:
#- targets: ["localhost:9090"]
- targets: ["localhost:9182"]
4.Prometheusの実行
PowerShellを起動し、以下のコマンドを実行する。
> C:\systemwatch\prometheus\prometheus.exe --config.file=C:\systemwatch\prometheus\prometheus.yml --web.listen-address=:9095
※最後のパラメータは起動するポート番号。デフォルトは9090ですが、バッティングしている場合は上記のように指定し、別ポートを利用します。
なお、すでにポートが使われているかは以下のコマンドをコマンドプロンプトで実行することで把握が可能。
> netstat -ano | find "9090"
以下の画面が出てくれば問題なし。
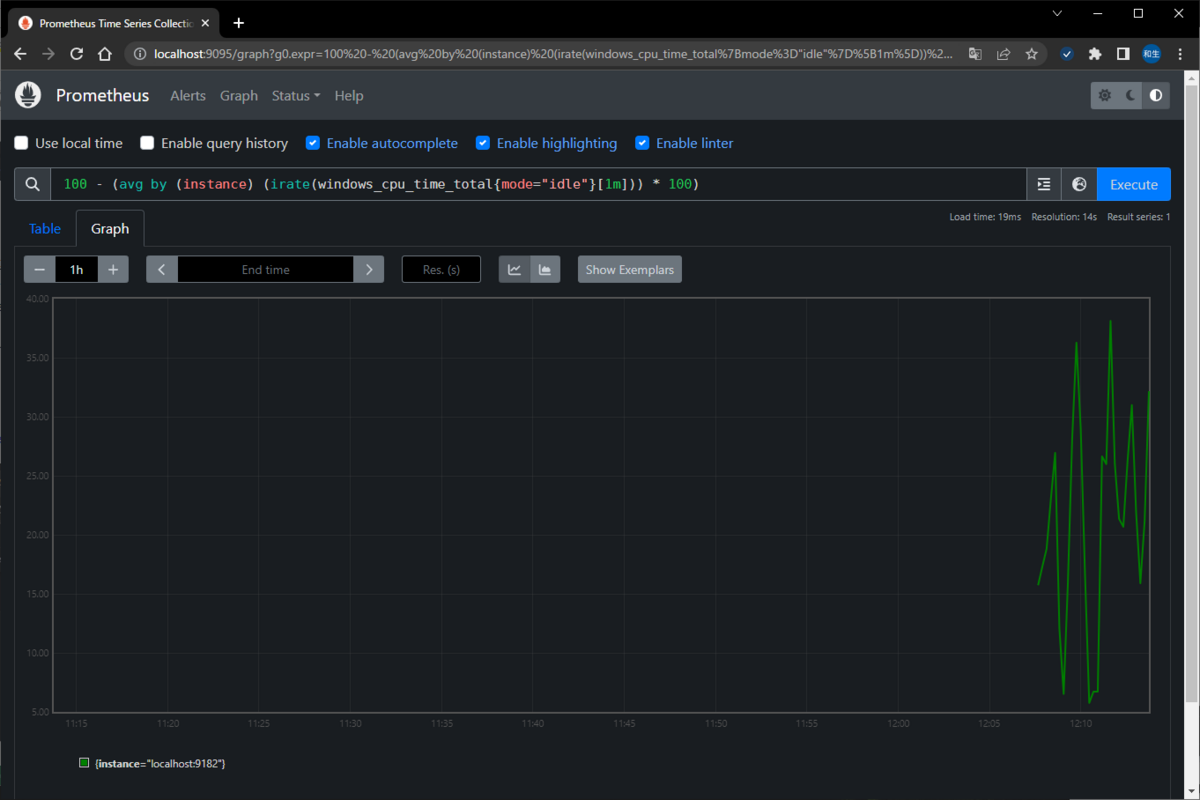
5.ブラウザにて以下のURLにアクセスを行う
検索欄の右側にある[地球儀マーク](?)を押下し、見たいデータを選択。[Execute]を押下してデータを確認することが可能となります。
ただし、それだけでは欲しい情報は手に入らないため、以下の内容で表示することで、それぞれの情報を確認できます。
ただし、表示に関してはとても簡素なので、見やすさ的にはやはりGrafanaと連携した方が良いと思われます。
▽CPU使用率
・コアすべてをまとめて表示
100 - (avg by (instance) (irate(windows_cpu_time_total{mode="idle"}[1m])) * 100)
・CPU使用率(コア/スレッド毎)
rate(windows_cpu_processor_utility_total[5m]) / rate(windows_cpu_processor_rtc_total[5m])
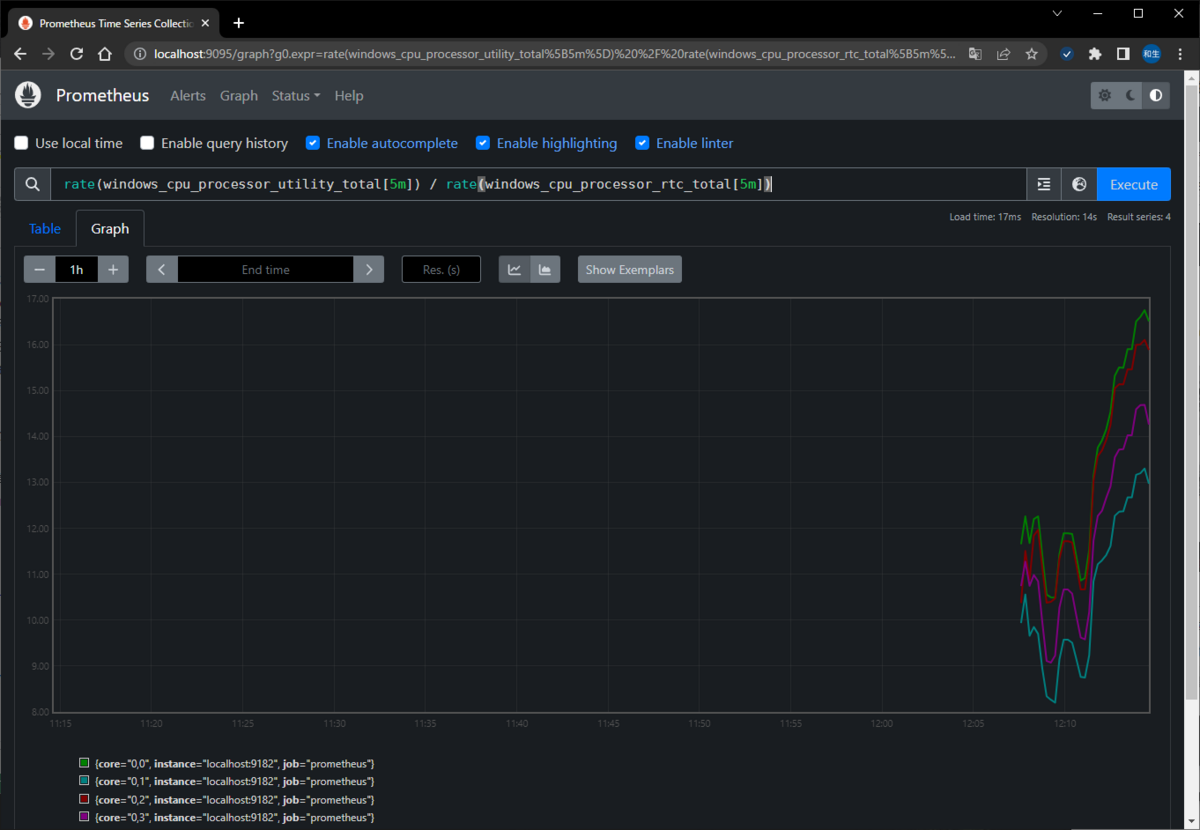
▽メモリ使用率
100 - (windows_os_physical_memory_free_bytes / windows_os_visible_memory_bytes * 100)
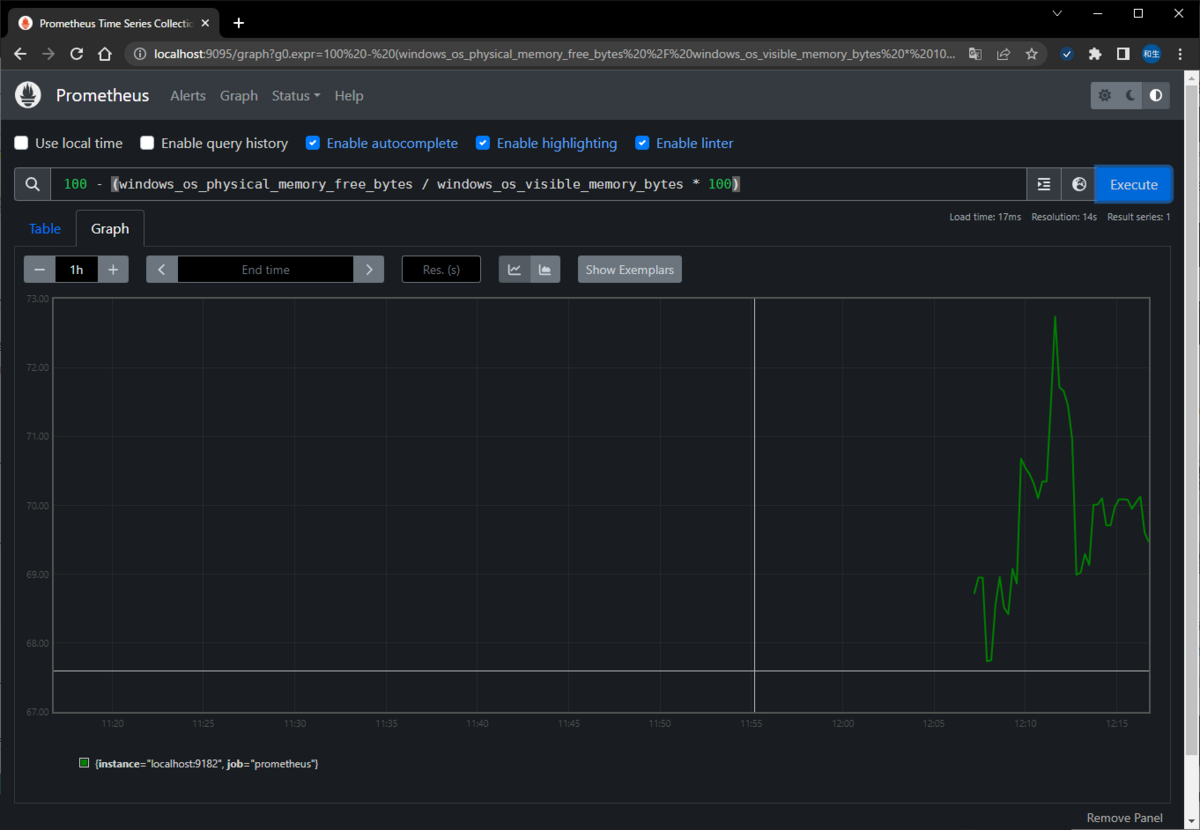
▽メモリ使用量
・メモリ使用可能量
windows_os_visible_memory_bytes / 1024 / 1024 / 1024
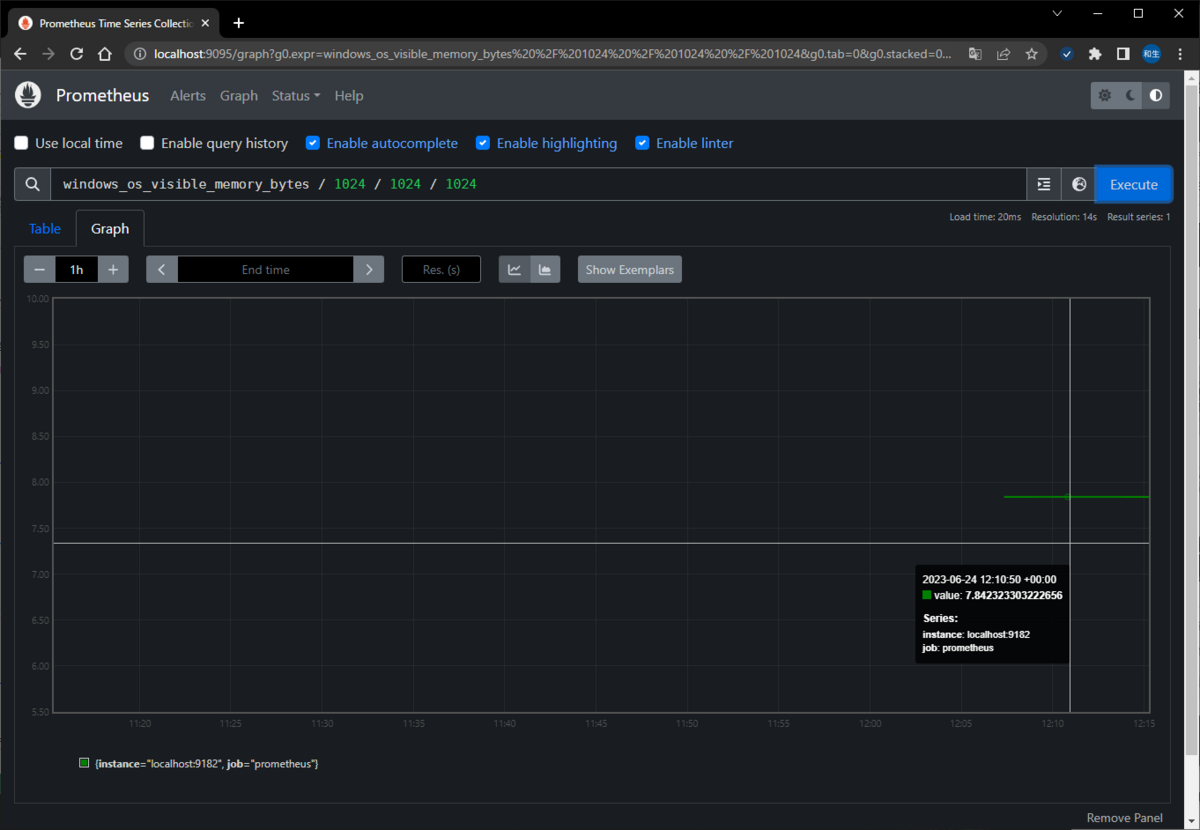
・メモリ使用量
(windows_os_visible_memory_bytes - windows_os_physical_memory_free_bytes) / 1024 / 1024 / 1024
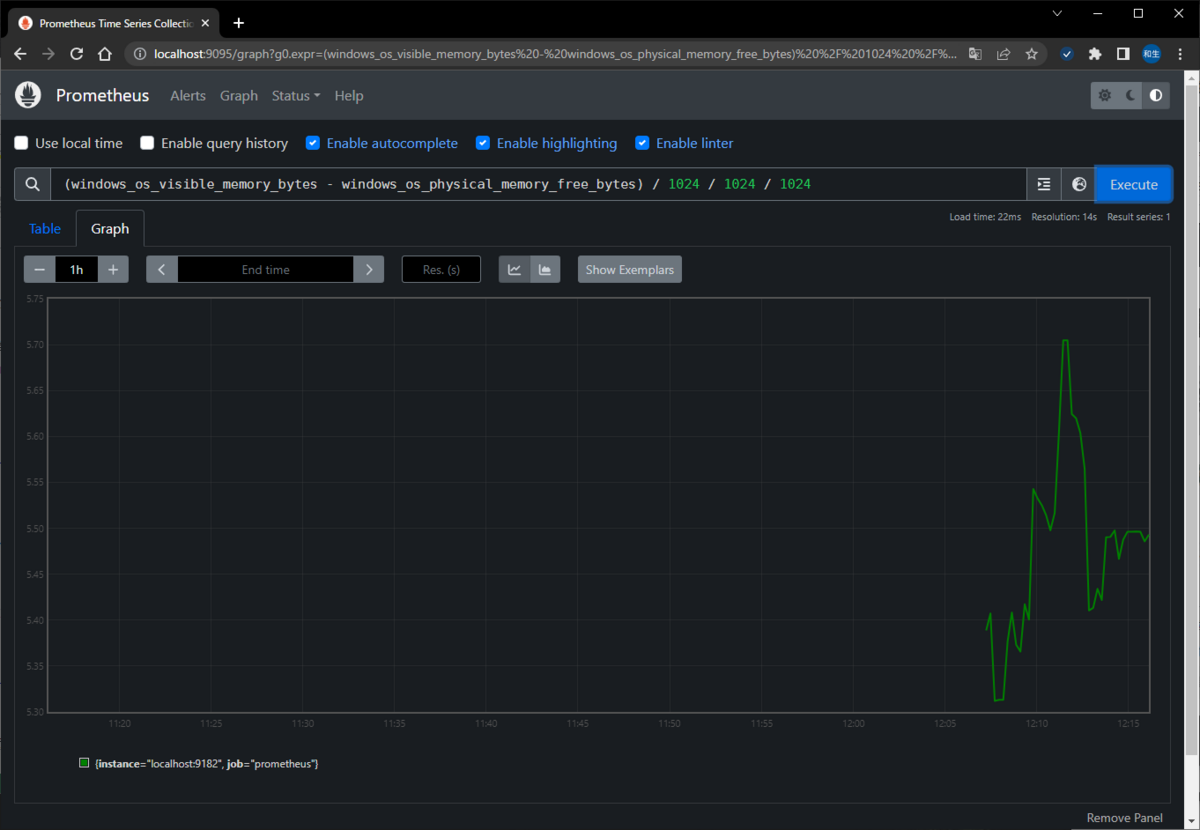
▽HDD使用率(例としてCドライブを指定)
100 - (windows_logical_disk_free_bytes{volume = "C:"} / windows_logical_disk_size_bytes{volume = "C:"} * 100)
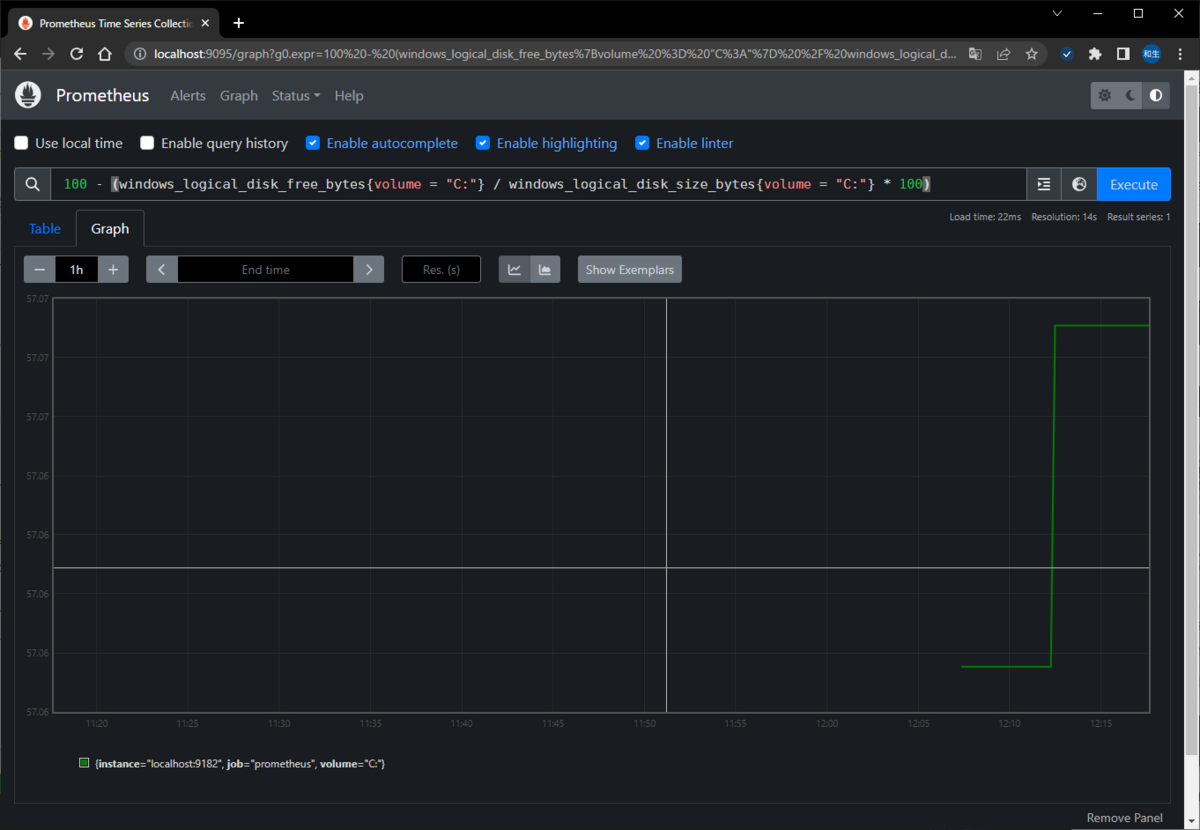
▽HDD空き容量
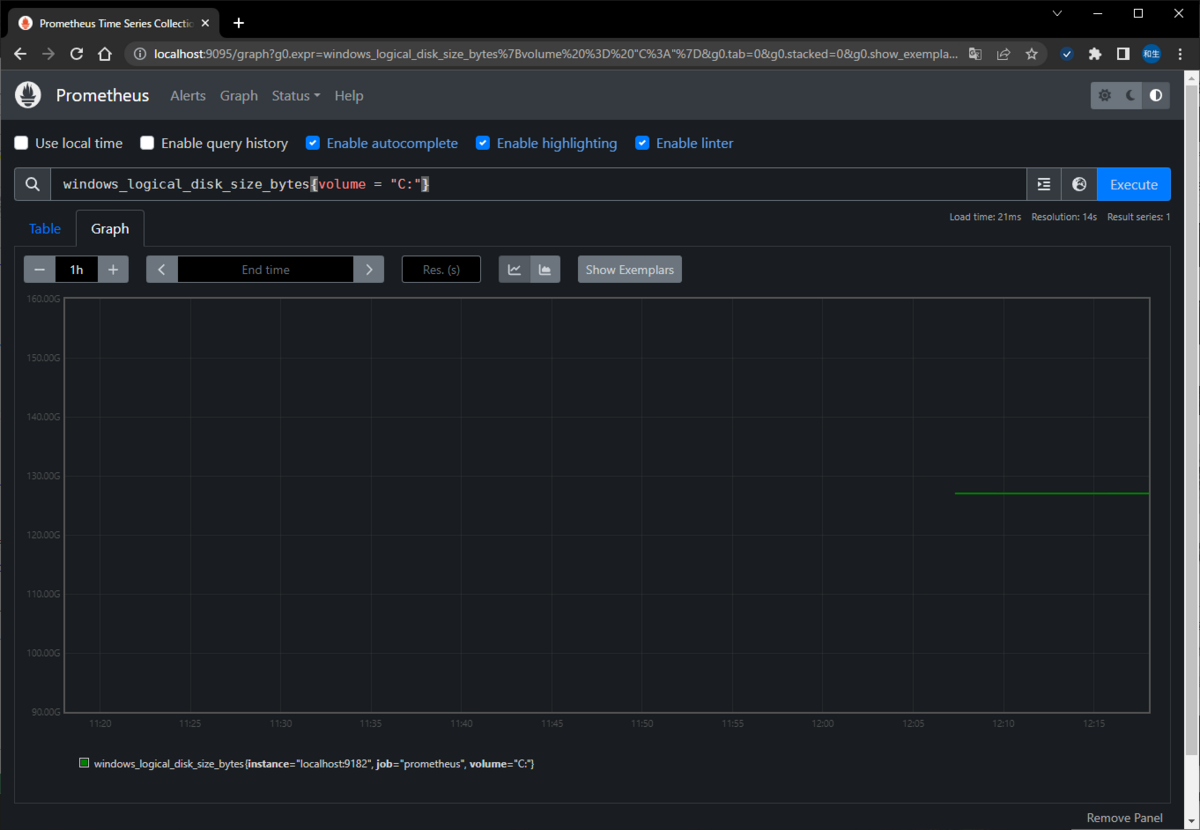
・使用可能領域(例としてCドライブを指定)
windows_logical_disk_size_bytes{volume = "C:"}
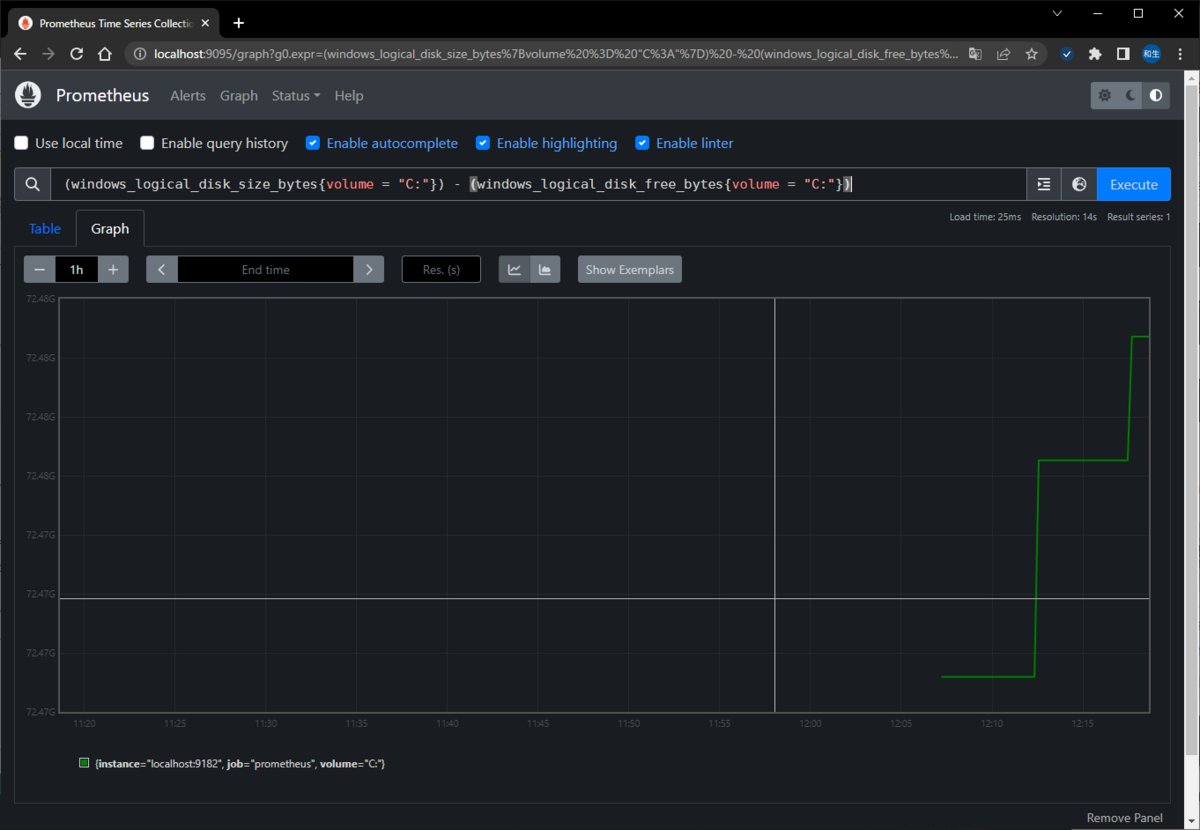
・使用済領域(例としてCドライブを指定)
(windows_logical_disk_size_bytes{volume = "C:"}) - (windows_logical_disk_free_bytes{volume = "C:"})
40万PV達成しました。
というわけで、久々の大台。
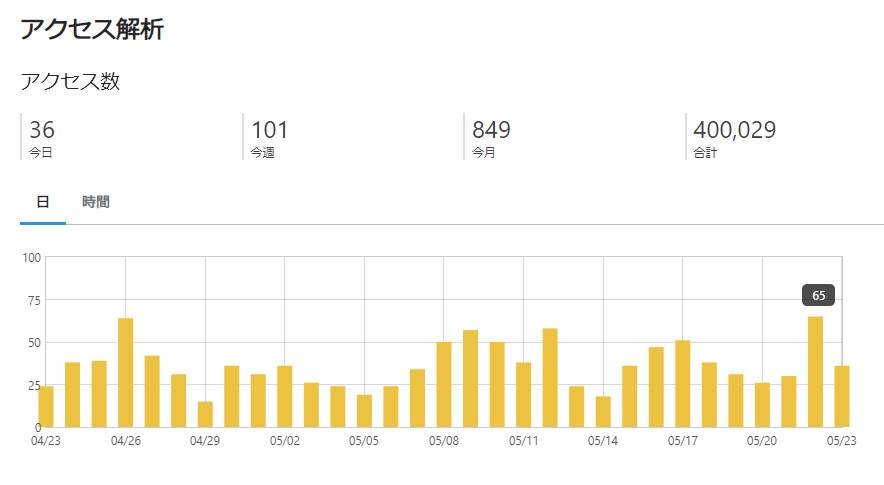
20万が2018年だったようで。
engetu21.hatenablog.com
30万はいつの間にか行ってた模様。
大体2年ぐらいで10万PV?
40万が近いことは確認してたけど、多分10月ぐらいだろうなぁと思っていたら、思ったより早く到達。
どうやら「WindowsSever2019 タスクスケジューラ」でググると一番上に表示されるようになったようで、
それでアクセス数が伸びたようです。
割と力抜いて記載したものが、アクセス数伸びるってのも多少モヤるものの、
まぁ取り扱ってるネタが、軽いものかかなりマニアックなものしかないのでしょうがないですね。
最近の傾向といいますか、Twitterで英知を分け与える人がいるものの、それ自体はその性質上、かなり流動的かつ検索にも引っかからないことが多いため、情報の蓄積という観点でいうと、世の中は大分弱くなったのではという印象ですね。日本的にはYahoo!ブログが終了したのは大きい。また、昨今Youtubeなどでの解説動画が盛んですが、同様に蓄積という観点ではやはり文字に負けると思います。ブログよりお金になるからやるのでしょうけど、正直、事細かな部分はフォローしきれない部分も出てきますし。
金になるということであれば、40万PVと抜かしてるものの、このブログはほぼアフィもやってない(たまにAmazonのリンクを貼るぐらい)ですが、まったく金にはなってないです。まぁそれでも続けてるのは、アウトプットしておくと後々自分が助かるし、誰かの助けにもなる。各種OSSを利用させてもらってる手前、誰かの役に立つかもという姿勢はとても大事だと思ってます。
最悪なのはいかがでしたか系ブログで、自分で試してもないネット記事情報を引用したものばっかりでろくなものじゃないです。まぁ毎日更新でアフィってなるとそうならざるを得ないのはわかりますが。また、謎に文章コピーを規制しているブログも。私自身は技術ブログはコピペできてなんぼだと思ってるので、規制するぐらいなら公開しなくていいのではと思うぐらいには無意味に感じます。書いてあるコマンドをわざわざ入力はちょっとね…令和になってまでドラクエの復活の呪文入力みたいなことはしたくないです。
chatGPTの登場もありますが、調べる点については特化していきそうですが、逆にこういった技術的な情報を残す側は今後どんどん減っていくかもしれませんね。困ってる割には自分でチャレンジする人は減ってるような気がします。まぁ失敗するならやらない、というのもとてもわかりますが、こと技術系というのはトライ&エラーなので、それができない人は周りについていけなくなってしまうのではと感じています。
このブログも気ままに書いてますが、いつか何かあれば更新が止まる時が来るかもしれません。
それまではまぁ、いままで通り、思いついて試して書いて…をゆるくやっていこうかと。
【Windows10】【AI】Real-ESRGANで画像ファイルの画質向上を試す
RTX 3060(GG-RTX3060-E12GB/OC/DF)を買いました。
Stable diffusionでAIに画像作らせるのは面白いですね。
まぁそれは今回置いておくとして、ガビガビ画像をAIによる画質向上を目的に「Real-ESRGAN」の導入してみます。
といっても、Stable diffusion内でも同様のことができるっちゃできますが、まぁこれは勉強ということで。
参考サイト:【Real-ESRGAN】Webアプリ・ツールの導入方法 | ジコログ
というわけでお題目。
1.CUDAのインストール
Windows10にReal-ESRGANを入れるにはまずPyTorchが必要。そしてPyTorchを使うためにCUDAを入れます。
developer.nvidia.com
最新のCUDA Toolkit 12.1.1 をダウンロード。
インストーラはローカル版とネットワーク版があるけど、今回はローカル版。
インストーラをダウンロード後、インストールを実行。

パッケージのインストールを自動で行ってくれるため、終了まで待機。
導入確認はpowershellでコマンド実行で確認することが可能。
> nvcc -V nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2023 NVIDIA Corporation Built on Mon_Apr__3_17:36:15_Pacific_Daylight_Time_2023 Cuda compilation tools, release 12.1, V12.1.105 Build cuda_12.1.r12.1/compiler.32688072_0
2.PyTorchのインストール
PyTorchはつい最近(3/16)にVer2.0がリリースされ、1.x系より性能が向上されたらしい。
なので、今回は2.0をインストールします。
PyTorchはpipコマンドでインストールを行います。
powershellを起動し、以下のコマンドを実行する。なお、Pythonのバージョンは3.10.6。
一応、その前にpipとsetuptoolsのアップデートをしてから実行します。
> py -m pip install --upgrade pip setuptools > py -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 Looking in indexes: https://download.pytorch.org/whl/cu118 Collecting torch Downloading https://download.pytorch.org/whl/cu118/torch-2.0.1%2Bcu118-cp310-cp310-win_amd64.whl (2619.1 MB) --------------------------------------- 2.6/2.6 GB 2.5 MB/s eta 0:00:01
pyコマンドはpythonコマンドとほぼ同様といえば同様ですが、一応説明すると、
Pythonが異なるバージョンで2種類以上インストールされている場合に、pyコマンドを実行すると最新のバージョンで実行してくれます。
Pythonは3.10と3.9といったように、マイナーバージョンが異なると別者扱いになるため、
常に最新を使いたい場合はpyコマンドを使えばいい、という工夫(苦肉の策)だそうです。
ただし、これはWindows限定だったはず(たしか)。
コマンドを実行すると2.5GBぐらいのダウンロードがまず始まるため、気長に待ちます。
特に問題がなければ完了。
インストールができたかはpip listで確認可能。
> py -m pip list torch 2.0.1+cu118 torchaudio 2.0.2+cu118 torchvision 0.15.2+cu118
Pythonで実行できるかどうかは、Pythonで以下のように実行。
> py ※以下をコピペし、実行します。 import torch print(torch.__version__) print(torch.cuda.is_available()) ※以下のように出れば問題なし 2.0.1+cu118 True
3.Real-ESRGANのインストール
3.1 Real-ESRGANのWebアプリのダウンロード
Real-ESRGANのWebアプリを最新で使うため、Webアプリを以下のサイトからソースを取得します。
(GitHubにあるものは古く、Python3.10には対応していないらしい)
huggingface.co
GitHubと違い、ZIP化してダウンロードができないらしい。
全ソースのダウンロードを実施するには、pipでhuggingface-hubのパッケージを導入するのが手っ取り早い。
> py -m pip install huggingface-hub
huggingface-hubを導入後、pyコマンドでpythonプロンプトを開く
> py
※以下をコピペし、実行します。
from huggingface_hub import snapshot_download
snapshot_download(
repo_id="akhaliq/Real-ESRGAN",
repo_type="space",
revision="main",
cache_dir="./")ダウンロードしたファイルはpyコマンドを実行したフォルダの配下に、「spaces--akhaliq--Real-ESRGAN」というフォルダ名で格納されています。
3.2 Real-ESRGAN本体のインストール
github.com
こちらから、[Code]→[Download ZIP]でソースをダウンロードします。
ダウンロード後、好きなところにファイルを解凍します。
今回は「C:\Real-ESRGAN-master」に作成します。
解凍後、3.1でダウンロードしたWebアプリが入っているフォルダである「spaces--akhaliq--Real-ESRGAN」→「snapshots」→「ce98fc29358a5b69f9268d7d60b2ea22b25d82c4」の中身をすべてコピーし、Real-ESRGAN本体のフォルダ(C:\Real-ESRGAN-master配下)に、ファイルを上書きする形でペーストします。
※なお、「ce98fc29358a5b69f9268d7d60b2ea22b25d82c4」から始まるフォルダ名はリポジトリバージョンなので可変です。
コピペが完了後、powershell上でC:\Real-ESRGAN-masterに移動します。
その配下にrequirements.txtというテキストファイルがありますが、これにはReal-ESRGANを使うためのpipパッケージが記載されているため、
このテキストファイルををpipコマンドで指定し、Real-ESRGANの実行に必要となるパッケージ群をマルっとインストールしてもらいます。
> cd C:\Real-ESRGAN-master > py -m pip install -r requirements.txt
4.Real-ESRGANのセッティング
4.1 モデルのダウンロード
Stable diffusionでも実写風やイラスト風で仕上げるのにモデルを選択したように、Real-ESRGANでもモデルが必要になります。
Real-ESRGANでは、実写風であれば「base」、イラスト風であれば「anime」と画面上で選択できるようなので、
それぞれのモデルをgithubからダウンロードします。
ダウンロードは、以下URLをブラウザのアドレスバーに貼ってアクセスすることで可能です。
◆base:RealESRGAN_x4plus.pth
https://github.com/xinntao/Real-ESRGAN/releases/download/v0.1.0/RealESRGAN_x4plus.pth
◆anime:RealESRGAN_x4plus_anime_6B.pth
https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.2.4/RealESRGAN_x4plus_anime_6B.pth
ダウンロードしたファイルは「C:\Real-ESRGAN-master」の直下に配置します。
4.2 プログラムファイルの変更
「C:\Real-ESRGAN-master」の直下にあるapp.pyの中身を修正します。
INPUT_DIR = "/tmp/input_image" + str(_id) + "/"
OUTPUT_DIR = "/tmp/output_image" + str(_id) + "/"
↓
INPUT_DIR = "./tmp/input_image" + str(_id) + "/"
OUTPUT_DIR = "./tmp/output_image" + str(_id) + "/"INPUT_DIRとOUTPUT_DIRは「/tmp/~」となっていますが、もともとLINUXで動作をする前提のため、
ルート直下のtmpディレクトリが記載されていますが、「.」(ピリオド)を追加することで、「C:\Real-ESRGAN-master」配下の「tmp」を示す形に変更しています。
そのため、「C:\Real-ESRGAN-master」配下に「tmp」フォルダを作ることを忘れずに実施します。(該当フォルダが無いと画面での実行時にエラーになります)
次に、以下の部分は起動のたびにTEMPフォルダの削除と作成を実施していますが、
rmコマンド、mkdirコマンドについてもLINUXコマンドとなるため、Windows用に変更を加えます。
run_cmd("rm -rf " + INPUT_DIR)
run_cmd("rm -rf " + OUTPUT_DIR)
run_cmd("mkdir " + INPUT_DIR)
run_cmd("mkdir " + OUTPUT_DIR)
↓
if os.path.isdir(INPUT_DIR):
os.rmdir(INPUT_DIR)
else:
os.mkdir(INPUT_DIR)
if os.path.isdir(OUTPUT_DIR):
os.rmdir(OUTPUT_DIR)
else:
os.mkdir(OUTPUT_DIR)次にwgetをしてる部分ですが、4.1にてモデルをすでにダウンロードしているため、こちらもコメントアウトします。
run_cmd("wget https://github.com/xinntao/Real-ESRGAN/releases/download/v0.1.0/RealESRGAN_x4plus.pth -P .")
os.system("wget https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.2.4/RealESRGAN_x4plus_anime_6B.pth -P .")
↓
# run_cmd("wget https://github.com/xinntao/Real-ESRGAN/releases/download/v0.1.0/RealESRGAN_x4plus.pth -P .")
# os.system("wget https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.2.4/RealESRGAN_x4plus_anime_6B.pth -P .")次に、app.pyの中で、リサイズしている箇所があるため、画質向上のため、こちらもコメントアウトします。
basewidth = 256
wpercent = (basewidth/float(img.size[0]))
hsize = int((float(img.size[1])*float(wpercent)))
img = img.resize((basewidth,hsize), Image.ANTIALIAS)
↓
# basewidth = 256
# wpercent = (basewidth/float(img.size[0]))
# hsize = int((float(img.size[1])*float(wpercent)))
# img = img.resize((basewidth,hsize), Image.ANTIALIAS)
5.Real-ESRGANの実行
これまでの準備で問題がなければ、以下のコマンドでReal-ESRGANが起動します。
「C:\Real-ESRGAN-master」配下に移動し、pyコマンドを実行。
> cd C:\Real-ESRGAN-master > py app.py
Running on local URL: http://127.0.0.1:7860/
と出れば成功。
ブラウザからアクセスすると、以下の画面が表示されます。

後は画面にしたがって実行してみますが、サンプルで試すとこうなります。

明らかにくっきりはっきり大きくなっており、これはなかなか。
後はネットで拾った画像もこんな感じに。いいですね。とても面白い。



【Python 3.x】e-StatからのデータをAPIで取得
e-Statは政府が提供している統計データですが、ものによってはAPIを提供しているため、Pythonで気軽に取得することが可能です。
www.e-stat.go.jp
例えば、国勢調査の男女別人口及び人口性比に関しては、以下のページからWebで確認することができます。
www.e-stat.go.jp
このページの左端にある表示項目選択を開くと、表示する項目を選択することができます。
選択後、ページ右にあるAPIボタンを押すことでXML/JSON/CSVのそれぞれの形式でファイルが取得できるAPIを取得することが可能。
今回は以下のような条件で取得
・表彰項目:人口、人口性比
・男女_時系列:男、女
・地域_時系列:都道府県全て(全国、人口集中地区、人口集中地区以外の地区は除外)
・時間軸(調査年):全て
Pythonのプログラムで取得する場合は、以降に記載するプログラムのように組めば行けます。
requestsモジュールを使うため、入れてない場合はpipで導入することをお勧めします。
python -m pip install requests
ちなみに、APIを利用する場合は、appIdを利用する必要があります。appIdはe-statでユーザ登録しないと入手できないため、あらかじめ登録作業が必要になります。
詳しくはこちら。
www.e-stat.go.jp
APIの仕様は以下に記載されています(現在は3.0)。
www.e-stat.go.jp
テストフォームを利用して、あらかじめAPIの確認も可能です。
https://www.e-stat.go.jp/api/sample/testform3-0/
というわけでプログラム。
import requests
import sys
# --CSVファイルパス
CSV_PATH = r"C:\Users\hoge\Desktop" + "\\"
url = "http://api.e-stat.go.jp/rest/3.0/app/getSimpleStatsData"
cdArea="01000,02000,03000,04000,05000,06000,07000,08000,09000,10000,11000,12000,13000,14000,15000,16000,17000,18000,19000,20000,21000,22000,23000,24000,25000,26000,27000,28000,29000,30000,31000,32000,33000,34000,35000,36000,37000,38000,39000,40000,41000,42000,43000,44000,45000,46000,47000"
cdCat01="110,120"
cdTab="020"
appId="testtesttesttesttesttesttesttesttesttesttesttesttesttesttest"
lang="J"
statsDataId="0003410379"
metaGetFlg="N"
cntGetFlg="N"
explanationGetFlg="N"
annotationGetFlg="N"
sectionHeaderFlg="2"
replaceSpChars="0"
# --HTTPリクエスト実行
def request() :
params = {
'cdArea':cdArea
, 'cdCat01':cdCat01
, 'cdTab':cdTab
, 'appId':appId
, 'lang':lang
, 'statsDataId':statsDataId
, 'metaGetFlg':metaGetFlg
, 'cntGetFlg':cntGetFlg
, 'explanationGetFlg':explanationGetFlg
, 'annotationGetFlg':annotationGetFlg
, 'sectionHeaderFlg':sectionHeaderFlg
, 'replaceSpChars':replaceSpChars
}
filename = 'kokusei.csv'
response = requests.get(url, params=params) #GETメソッドで情報を取得
response.encoding = response.apparent_encoding
res_list = []
res_list = response.text.split()
#print(response.text)
if "STATUS" in res_list[1]: # 2行目にSTATUS文字列が入っていた場合(返却がエラーの場合)
# print(f'{res_list[1]}:{res_list[2]}')
return
#print('API実行、データ取得完了')
f = open(CSV_PATH + filename, 'w', newline='', encoding='utf8')
f.write(response.text)
f.close()
# table_insert(filename, date)
return
try:
request()
except Exception as e:
# logger.error(f'エラー要因:{str(e)}')
sys.exit()
問題なくCSVに吐き出されると以下のような内容で取得できます。
"tab_code","表章項目","cat01_code","男女_時系列","area_code","地域_時系列","time_code","時間軸(調査年)","unit","value" "020","人口","110","男","01000","北海道","1920000000","1920年","人","1244322" "020","人口","110","男","01000","北海道","1925000000","1925年","人","1305473" "020","人口","110","男","01000","北海道","1930000000","1930年","人","1468540" "020","人口","110","男","01000","北海道","1935000000","1935年","人","1593845" <||